ADF Data Cube Operations
This section introduces the core operations of the ADF-DC API and illustrates these by examples. The core operations of the ADF-DC API are creating data cubes, writing data into them and reading data out. As for reading and writing, it is also possible to work with subsets of data.
Accessing the DataCubeService
The main entry point to the Data Cube API is the interface DataCubeService.
Given an ADF file adfFile of type AdfFile, an instance of this service may be retrieved as follows:
JAVA and C#:
DataCubeService dataCubeService = adfFile.getDataCubeService();
The DataCubeService (AdfService) allows in particular creating new data cubes and opening existing ones. Please refer to the JavaDoc of DataCubeService for more details.
Creating a Data Cube
The API provides methods to create multi-dimensional data cubes. Data Cubes may either be created from scratch or by reusing existing structure definitions. The following sections describe both approaches.
Creating a Data Cube from scratch
A Data Cube is defined by its structure. This structure consists of measures and dimensions. The following sections illustrate how this structure may be defined and thus a Data Cube be created from scratch.
Defining the IRI and the label of the Data Cube
Each Data Cube must be uniquely identified by an IRI and must have a label.
The following example illustrates how both can be defined:
JAVA:
@Autowired
private IRIFactoryI iriFactory;
...
DataCubeService dataCubeService = adfFile.getDataCubeService();
IRI dataCubeIRI = iriFactory.create("urn:example:DataSeries");
DataCube dataCube = dataCubeService.createDataCube(dataCubeIRI, "Data Series") //
....
C#:
@Autowired
public org.apache.jena.iri.IRIFactoryI IriFactory { protected get; set; }
...
DataCubeService dataCubeService = adfFile.getDataCubeService();
IRI dataCubeIRI = IriFactory.create("urn:example:DataSeries");
DataCube dataCube = dataCubeService.createDataCube(dataCubeIRI, "Data Series") //
....
where dataCubeIRI denotes the IRI of type IRI of this data cube.
Defining measures
Measures may be defined using the method MeasureDimension withMeasure(Property measure, DataType dataType, OrderFunction orderFunction, Object fillValue) or one of its convenience methods provided by the interface MeasureOnly - please refer to its JavaDoc for details.
For each measure, at least the following information MUST be specified:
- the Property that is measured
- the data type of the measured property
Since the Property is the primary identifier and also the definition for the measurement, it has to be unique among all measures of a DataCube.
JAVA and C#:
private Property measureXYZ = ...; // some property from AFT
...
DataCube dataCube = dataCubeService.createDataCube(dataCubeIRI, "Data Series") //
.withMeasure(measureXYZ, StandardDataType.INT) //
...
In this example, measureXYZ is a value from an AFT and int is used as data type for the measured property.
The data types supported by the ADF-DC API are described here.
Supported Data Types
Standard Data Types
ADF-DC API supports the following data types (enum StandardDataType) for measures, dimensions and scales:
- BYTE
- SHORT
- INT
- LONG
- FLOAT
- DOUBLE
- BOOLEAN
- STRING
- IRI
- DATE_TIME via LONG
The mapping of these data types is described in the specification of ADF-DC API [[ADF-DC]], e.g. xsd:short maps to Java's short class, etc.
Complex Data Types
ADF-DC API also supports complex data types for measures, dimensions and scales. Complex data types are combinations of default data types and/or other complex data types.
Example: A quantity value, which always has a numerical value and a unit:
{
- DOUBLE (numerical value)
- IRI (fixed identifier of the unit, e.g. http://qudt.org/vocab/unit#MinuteTime)
}
Complex data types are defined by data shapes in the DataDescription. The example type would look like this:
http://purl.allotrope.org/shapes/example#MyQuantityValue
a http://www.w3.org/ns/shacl#Shape ;
http://www.w3.org/ns/shacl#property
[ http://www.w3.org/ns/shacl#class
qudt:Unit ;
http://www.w3.org/ns/shacl#hasValue
http://qudt.org/vocab/unit#MinuteTime ;
http://www.w3.org/ns/shacl#maxCount
"1"^^xsd:long ;
http://www.w3.org/ns/shacl#minCount
"1"^^xsd:long ;
http://www.w3.org/ns/shacl#predicate
qudt:unit
] ;
http://www.w3.org/ns/shacl#property
[ http://www.w3.org/ns/shacl#datatype
xsd:double ;
http://www.w3.org/ns/shacl#maxCount
"1"^^xsd:long ;
http://www.w3.org/ns/shacl#minCount
"1"^^xsd:long ;
http://www.w3.org/ns/shacl#predicate
qudt:numericValue
] .
The DataCubeService provides a factory method for one-time data type builders:
JAVA and C#:
// Creating the data type
DataTypeBuilder dtb = dataCubeService.createDataTypeBuilder();
IRI dataTypeIri1 = iriFactory.create("http://purl.allotrope.org/example#MyQuantityValue");
ComplexDataType dataType = dtb.createComplexDataType(dataTypeIri1) //
.withProperty(dtb.createProperty(QudtSchema.numericValue).withType(StandardDataType.DOUBLE).finish()) //
.withProperty(dtb.createProperty(QudtSchema.unit).withType(StandardDataType.IRI).withValue(QUDT_UNIT_MINUTE_TIME).finish()) //
.finish();
// Opening an existing data type
ComplexDataType sameDataType = dataCubeService.openDataType(dataTypeIri1);
A quantity value data type is just a special case of a complex data type. A more complex data type could look like the following where a value contains of two properties, a measurement and an uncertainty. For both properties we re-use the quantity value data type defined above (minutes encoded as DOUBLE).
JAVA and C#:
// Creating the complex data type
dtb = dataCubeService.createDataTypeBuilder(); // new builder for the next data type
IRI dataTypeIri2 = iriFactory.create("http://purl.allotrope.org/example#MyComplexDataType");
ComplexDataType complexDataType = dtb.createComplexDataType(myComplexDataType1) //
.withProperty(dtb.createProperty(TEST_PROP_MEASUREMENT).withType(dataTypeIri1).finish()) //
.withProperty(dtb.createProperty(TEST_PROP_UNCERTAINTY).withType(dataTypeIri1).finish()) //
.finish();
A ComplexDataType object can be used in measure and dimension configuration just like the primitive data types from the StandardDataType enum.
QuantityValueType must be used in every case where objects with a QUDT unit and a numeric value are concerned.
Defining dimensions
Dimensions may be defined using the method Dimension withDimension(Property dimension, DataType dataType, long size) or
one of its convenience methods (please refer to the JavaDoc for details) provided by the interface DimensionOnly.
For each dimension, at least the following information must be specified:
- the dimension property
- the data type of the dimension property
- the size of the dimension
Since the dimension property is the primary identifier and also the definition for the dimension, it has to be unique among all dimensions of a DataCube.
Basically, the size of the dimension must be fixed, i.e. it may not be changed after the Data Cube has been created. If one needs a dimension, whose range of values must be extensible or unlimited, using chunking should be considered.
In the following example, a Data Cube with two dimensions is created, having 40 entries in the first dimension and two in the second.
JAVA and C#:
Property measureXYZ = ...;
Property firstDimension = ...;
Property secondDimension = ...;
DataCube dataCube = dataCubeService.createDataCube(dataCubeIRI, "Data Series") //
.withMeasure(measureXYZ, StandardDataType.INT) //
.withDimension(firstDimension, StandardDataType.LONG, 40) //
.withDimension(secondDimension, StandardDataType.LONG, 2) //
.finish();
Dimensions are ordered, starting with 1.
The order is implicitly defined by the order of the invocations of withDimension().
Improving the storage layout of dimensions with chunking
The number of entries a dimension may hold determines its size. The ADF-DC API supports chunking to store these entries efficiently. Chunking means that the range of dimension values is separated into equidistant chunks. When using chunking in Data Cubes, only those chunks that actually hold values allocate storage space. Chunks that do not hold any values, do not require any storage space, thus no storage is wasted. Thus, chunking is particularly useful when having sparse data.
The following sections describe the size parameters that allow to configure chunking.
Defining the initial size of a dimension
The size of a dimension is determined by the number of entries it may hold. It is possible to define an initial size and a maximum size for a dimension.
When using chunking for a dimension, the initial size of this dimension must be defined. It may be smaller than or the same as the maximum size of the dimension.
The following example illustrates how the creation of a chunked dimension with an initial size of 40,000 entries:
JAVA and C#:
Property measureXYZ = ...;
Property firstDimension = ...;
Property secondDimension = ...;
Property thirdDimension = ...;
Property fourthDimension = ...;
DataCube dataCube = dataCubeService.createDataCube(dataCubeIRI, "Chunked DataCube") //
.withMeasure(...) //
.withChunkedDimension(firstDimension, StandardDataType.LONG, 40000) //
...
When using a chunked dimension, the chunk size must be defined. This is described in the following section.
Defining the chunk size of a dimension
The chunk size defines the maximum number of entries that each chunk of the dimension may contain.
The interface ChunkedDimension provides the methods Dimension withChunkSize(long chunkSize) and Dimension withChunkSize(long chunkSize, long maximumSize) to define this size.
The following example continues the example from the previous section and sets the chunk size to 50 entries:
JAVA and C#:
DataCube dataCube = dataCubeService.createDataCube(dataCubeIRI, "Chunked DataCube") //
.withMeasure(...) //
.withChunkedDimension(firstDimension, StandardDataType.LONG, 40000).withChunkSize(50) //
...
This means that the dimension consists of 40,000 entries / 50 entries per chunk = 800 chunks.
For more information about chunks, please visit the support page.
Defining the maximum size of a dimension
If the maximum size of a dimension is known in advance, it may be defined via Dimension withChunkSize(long chunkSize, long maximumSize).
If it is unknown or must be extensible, it may be defined as unlimited.
JAVA and C#:
...
.withChunkedDimension(firstDimension, StandardDataType.LONG, 10000).withChunkSize(30, DataCubeConfiguration.UNLIMITED) //
.withChunkedDimension(secondDimension, StandardDataType.LONG, 80).withChunkSize(50, 250) //
...
In order to set the size to unlimited, the constant DataCubeConfiguration.UNLIMITED may be used.
Complete Example
This section gives a complete example of a Data Cube that uses chunking for some of its dimensions:
JAVA and C#:
DataCube dataCube = dataCubeService.createDataCube(dataCubeIRI, "Chunked DataCube") //
.withMeasure(measureXYZ, StandardDataType.INT) //
.withChunkedDimension(firstDimension, StandardDataType.LONG, 40000).withChunkSize(50) //
.withDimension(secondDimension, StandardDataType.LONG, 50) //
.withChunkedDimension(thirdDimension, StandardDataType.LONG, 80).withChunkSize(50, 250) //
.withChunkedDimension(fourthDimension, StandardDataType.LONG, 10000).withChunkSize(30, DataCubeConfiguration.UNLIMITED) //
.finish();
The first dimension has a size of 40,000 entries and a chunk size of 50 entries. The second dimension has a fixed size of 50 entries and does not use any chunking. The third dimension has an initial size of 80 entries, a maximum size of 250, and a chunk size of 50 entries. The fourth dimension has an initial size of 10,000 entries, an unlimited maximum size, and a chunk size of 30 entries.
Defining scales on dimensions
The ADF-DC API allows the creation of data cubes that have scales on their dimension(s).
Scales respectively scale types determine which kinds of selections are possible on dimensions.
Scales may be defined via the interface DimensionScale.
The API distinguishes between explicit scales and functional scales.
Explicit scales are scales whose values are materialized in HDF5.
Functional scales are scales whose values are represented by a function in RDF and are not materialized in HDF5.
The following sections describe both categories.
Explicit scales
The interface DimensionScale provides methods to create explicit scales,
notably the methods Dimension withExplicitScale(DataSelection dataSelection, ScaleType scaleType) and
Dimension withExplicitScale(DataSelection dataSelection, ScaleType scaleType, OrderFunction orderFunction).
An order function specifies the comparison of values for a component specification.
As order functions have not been implemented in ADF V1.1.0, the latter method may not yet be used.
The method withExplicitScale(DataSelection dataSelection, ScaleType scaleType) adds an explicitly defined scale to the last configured dimension.
A scale may be explicitly defined by a Data Selection that contains the scale values and by the type of scale being used.
The following scale types are supported (see enum ScaleType):
- Nominal scale
- Ordinal scale
- Cardinal scale
- Interval scale
- Ratio scale
The scale type is mostly metadata you can attatch to your DataCube for yourself or other users. Relevant for the ADF library itself is only if the scale values are
not sorted (nominal scale) or sorted (all other scale types). This way the ADF library can use faster search algorithms. In no case will the ADF library change the
order of the scale values.
This means, if...
...your scale values are not sorted declare the scale to be a nominal scale.
...your scale values are sorted, but you do not know exactly what kind of scale they represent or it does not matter for your work declare it to be an ordinal scale.
...you know what kind of scale your scale values represent use the ScaleType that best fits your scale values.
By default, the method withExplicitScale(DataSelection dataSelection, ScaleType scaleType) uses no order function for nominal scales and natural, lexicographic or quantity value order for simple values. An order function for a complex data type has to be definded and set manually.
The following example illustrates how an ordinal scale may be defined on a dimension:
JAVA and C#:
DataCube dataCube = dataCubeService.createDataCube(dataCubeIRI, "Data Cube with Scales") //
.withMeasure(...) //
...
.withDimension(firstDimension, StandardDataType.INT, 5).withExplicitScale(scaleSelection, ScaleType.ORDINAL) //
...
.finish();
The Data Selection scaleSelection that contains the scale values for each of the five dimension entries may look like this:
JAVA and C#:
DataSelection scaleSelection = dataCubeService.wrap(new int[] { 0, 3, 4, 9, 13 }).createSelectionAll();
Thus, we get the following scale values:
| Scale Entry | Scale Value |
|---|---|
| 0 | 0 |
| 1 | 3 |
| 2 | 4 |
| 3 | 9 |
| 4 | 13 |
For complex data types with only one variable property the Data Selection may contain instances of the complex data type (without providing a property path) or it contains only the variable, primitive values and the property path defines (like an XPath in XML documents) where in the complex data type the primitive values should end up.
E.g. for this data type:
{
- urn:property1 {
- urn:property1.1
- urn:property1.2
- urn:property2
In this case one can provide a Data Selection containing only the primitive values for property1.1 by using a property path consisting of Property instances representing "urn:property1", "urn:property1.1".
To summarize: For each entry of the dimension, we have one scale value. These scale values are stored explicitly in HDF5.
Functional scales
Functional scales are scales whose values may be represented by a function.
The ADF-DC API allows to create functional scales via the interface DimensionScale.
This interface provides the method Dimension withFunctionScale(FunctionType functionType, double factor, double constant), which allows to define the function to be used for the scale values of the last configured dimension.
The API supports linear and logarithmic functions. The following pre-defined types of functions (enum FunctionType) may be used:
- Linear Function
- Binary Logarithm
- Common Logarithm
- Natural Logarithm
In order to define a linear function, two parameters (a factor and a constant) must be defined. The following example shows how the linear function f(x) = 1.5 * x + 8.5 may be defined as functional scale for the dimension:
JAVA and C#:
DataCube dataCube = dataCubeService.createDataCube(dataCubeIRI, "Data Cube with Scales") //
.withMeasure(...) //
...
.withDimension(firstDimension, StandardDataType.DOUBLE, 10).withFunctionScale(FunctionType.LINEAR_FUNCTION, 1.5, 8.5) //
...
.finish();
Thus, we get the following scale values:
| Scale Entry (= x) | Scale Value (= f(x)) |
|---|---|
| 0 | 8.5 |
| 1 | 10 |
| 2 | 11.5 |
| 3 | 13 |
| 4 | 14.5 |
| 5 | 16 |
| 6 | 17.5 |
| 7 | 19 |
| 8 | 20.5 |
| 9 | 22 |
To summarize: For each entry of the dimension, we have one scale value that is generated by the function defined for this scale. As the function is represented in RDF, the scale values do not have to be stored explicitly.
Using Order Functions
Order functions define how values are ordered/sorted. They work like a Comparator in Java or an IComparer in C#. And (like in Java and C#) if no specific order function is given, the natural order function for the data type is chosen automatically. The order function types can be found in the org.allotrope.adf.enums.OrderFunctionType enum:
- Native Order is the natural order of numbers. This order function type can only be used with primitive numeric values.
- Lexicographical Order is the order used in dictionaries. This order function can only be used with Strings.
- Quantity Value Order defines the order of quantity value objects.
- Complex Value Order has to be defined specifically for each complex data type. It describes in which order the properties of the complex value objects are used to compare them by which order function. Since a property if a complex value object itself again can be a complex value object, sub-order-functions also can be complex value orders. But the final value comparison has to be defined on primitive properties by one of the other three order functions.
Example: Employees have to be ordered by last name, first name and income. The phone number does not have to be used in the order function. The following complex data type represents an employee.
{
- First name - urn:example-firstName - String
- Last name - urn:example-lastName - String
- Phone number - urn:example-phone - String
- Income - urn:example-income - quantity value {
- Value - qudt:numericalValue - double
- Currency - qudt:unit - IRI
}
The DataCubeService provides a factory method for one-time order function builders:
JAVA and C#:
// Creating the sub order function for the last name
OrderFunctionBuilder ofb = dataCubeService.createOrderFunctionBuilder();
IRI lastNameIri = iriFactory.create("urn:example-LastNameOrderFunction");
OrderFunction lastNameOrderFunction = ofb.createOrderFunction(lastNameIri, OrderFunctionType.LEXICOGRAPHIC_ORDER) //
.withPropertyPath(ResourceFactory.createProperty("urn:example-lastName")) //
.finish();
// Creating the sub order function for the first name
ofb = dataCubeService.createOrderFunctionBuilder();
IRI firstNameIri = iriFactory.create("urn:example-FirstNameOrderFunction");
OrderFunction firstNameOrderFunction = ofb.createOrderFunction(firstNameIri, OrderFunctionType.LEXICOGRAPHIC_ORDER) //
.withPropertyPath(ResourceFactory.createProperty("urn:example-firstName")) //
.withOrder(2) //
.finish();
// Creating the sub order function for the income
ofb = dataCubeService.createOrderFunctionBuilder();
IRI incomeIri = iriFactory.create("urn:example-IncomeOrderFunction");
OrderFunction incomeOrderFunction = ofb.createOrderFunction(incomeIri, OrderFunctionType.QUANTITY_VALUE_ORDER) //
.withPropertyPath(ResourceFactory.createProperty("urn:example-income")) //
.withOrder(3) //
.finish();
// Creating the main order function
ofb = dataCubeService.createOrderFunctionBuilder();
IRI orderFunctionIri = iriFactory.create("urn:example-MyOrderFunction");
OrderFunction myOrderFunction = ofb.createOrderFunction(orderFunctionIri, OrderFunctionType.COMPLEX_VALUE_ORDER) //
.withOrderFunction(lastNameOrderFunction) //
.withOrderFunction(firstNameOrderFunction) //
.withOrderFunction(incomeOrderFunction) //
.finish();
// Opening an existing order function
OrderFunction sameOrderFunction = dataCubeService.openOrderFunction(orderFunctionIri);
Important things to remember are:
- Create a new order function builder for each order function.
- The order in which the order functions are used while ordering is not defined by the order they are added to the complex order function. They have to be given an order value. The "last name" order function uses the default (1). The other two sub-order-functions have specific order numbers. So even if the calls during the creation of the complex order function would be done in a different order, the result would be the same.
Using compression in Data Cubes
The ADF-DC API allow using compression in Data Cubes. A precondition to use compression is a chunked data cube storage model.
The Finish interface provides the method Finish withZlibCompression(int level). It allows to set the level of compression for zlib compression. The following levels are supported:
- 0 - No compression
- 1 - Best speed (recommended if compression is desired)
- 9 - Best compression
The following example illustrates how compression in Data Cubes may be set up, using the level optimized for best speed:
JAVA and C#:
IRI dataCubeIri = ...
dataCubeService.createDataCube(dataCubeIri, "DataCubeWithCompression") //
.withMeasure(measureXYZ, StandardDataType.INT) //
// Compression can only be used on chunked DataCubes
.withChunkedDimension(firstDimension, StandardDataType.LONG, 1000).withChunkSize(1000) //
.withZlibCompression(1) //
.finish();
Creating a Data Cube by reusing an existing Data Cube Structure Definition
A Data Cube may be created by reusing an existing Data Cube Structure Definition (DSD).
The interface DataCubeService provides the method StructureConfig createDataCubeStructure(IRI iri) to create a reusable DSD.
The principle to create a DSD is similar to creating a Data Cube from scratch: One must define the measures and dimensions that each Data Cube adhering to this DSD is supposed to have. However, instance specific information such as the size of dimensions may not be defined.
The following example illustrates the creation of a reusable Data Cube Structure Definition:
JAVA and C#:
// Creates a DataStructureDefinition with two dimensions.
IRI dataStructureIri = ...
DataCubeStructureDefinition dataStructureDefinition = dataCubeService.createDataCubeStructure(dataStructureIri) //
.withMeasure(measureXYZ, StandardDataType.INT) //
.withDimension(firstDimension, StandardDataType.LONG) //
.withDimension(secondDimension, StandardDataType.LONG) //
.finish();
The following example illustrates reusing this structure for the creation of a Data Cube:
JAVA and C#:
// Creates a DataCube based on the previously created DataCubeStructureDefinition.
IRI dataCubeIri = ...
DataCube dataCube = dataCubeService.createDataCube(dataCubeIri, "DataCube using a DataStructureDefinition") //
.withStructure(dataStructureIRI) //
.withDimensionSize(2) //
.withDimensionSize(40) //
.finish();
To summarize: As one can see, only Data Cube instance specific values have to be configured when reusing an existing DSD.
Opening an existing Data Cube
The DataCubeService of the ADF-DC API provides the method DataCube openDataCube(IRI iri) to open an existing Data Cube via its IRI.
The following example illustrates opening an existing Data Cube:
JAVA and C#:
DataCube dataCube = dataCubeService.openDataCube(dataCubeIri);
Creating a Data Selection
When working with Data Cubes, there is often the need to work with subsets of data that it contains. These subsets are called Data Selections.
ADF-DCO defines a Data Selection as 'an n-dimensional subset of a data cube where the set of observations (i.e. the measures) are selected based on component selections on dimensions or measures'.
The DataCube interface provides two methods to create a Data Selection on a Data Cube:
- The method
SelectionConfig createSelection()allows the creation of a selection via a fluent API by defining for each dimension exactly which values must be selected and contained in the resulting selection. - The method
DataSelection createSelectionAll()allows the creation of a selection by selecting the complete content of the Data Cube, i.e. all of its data.
The ADF-DC API offers two possibilities to create Data Selections: by selecting values on dimensions or by selecting indices on indexed dimensions. The following sections describe both approaches.
Creating a Data Selection by selecting values on dimensions
This section describes how a Data Selection may be created by selecting certain values on a dimension of the Data Cube.
In order to create a Data Selection, for each dimension of the Data Cube a selection must be defined. The following types of selections are supported by the API:
- Point Selection
- Range Selection
Point Selection
The ADF-DC API offers two methods to create a point selection on a dimension that has a scale:
The method Dimension withDimensionValue(Object cellScaleValue) allows to select a single point on a dimension, whose scale has no floating point values. If the scale has floating point values, the method Dimension withDimensionValue(Object cellScaleValue, double precision) must be used that allows to specify the precision of the point selection.
The following example illustrates how to select a single point on the first dimension of a Data Cube, assuming that this dimension does not have floating point values.
JAVA and C#:
// Defines a DataSelection based on scale values.
DataSelection srcSelection = dataCube.createSelection() //
.withDimensionValue(5)
...
.finish();
Range Selection
This section describes how a Data Selection may be created by selecting a range of values on a dimension of the Data Cube.
The ADF-DC API offers two methods to create a range selection on a dimension that has an ordinal or cardinal scale:
The method Dimension withDimensionValueRange(Object startScaleValue, Object endScaleValue) allows to select a range on a dimension, whose scale has no floating point values.
If the scale has floating point values, the method Dimension withDimensionValueRange(Object startScaleValue, Object endScaleValue, double precision) must be used that allows to specify the precision of the point selection.
For the range, a lower bound and an upper bound must be defined. They are included in the range, i.e. one has a closed range.
The following example illustrates how to select the range from 1 to 5 on the first dimension of a Data Cube,
having the following scale values of type int:
[3, 5, 7, 9, 11, 13, 15, 17, 19, 21]
JAVA and C#:
DataSelection srcSelection = dataCube.createSelection() //
.withDimensionValueRange(1, 5) //
...
.finish();
The range of selected scale values contains the values 3 and 5.
The following example illustrates how to select a range on a dimension, whose scale values are of type floating point. The selected range is from -9 to -8.2 on the first dimension of a Data Cube
that has the following scale values of type double:
[-10.0, -9.5, -9.0, -8.5, -8.0, -7.5, -7.0, -6.5, -6.0, -5.5]
JAVA and C#:
DataSelection srcSelection = dataCube.createSelection() //
.withDimensionValueRange(-9, -8.2, 0.01) //
...
.finish();
The range selects the following scale values: -9 and -8.5. The number -8.2 is not a scale value, but it defines an interval ending with -8.5.
Creating a Data Selection by selecting indices on indexed dimensions
This section describes how a Data Selection may be created by selecting certain index positions on dimensions of the Data Cube. It is recommended to use these API features when having index scales or when performance is critical.
Introductory Example
Let's have a look at a 3x5 data cube. Say the cells marked in green are the ones we are interested in.
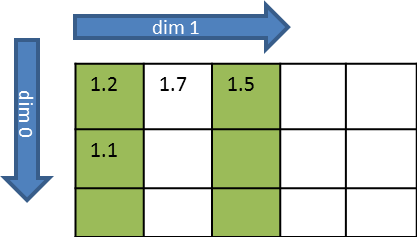
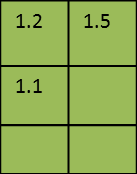
In order to select these cells, we define a data selection as follows: In dimension dim 0, we want to start at position 0 (starting position = 0) and take every cell (increment = 1) until the end (number of elements = 3). In dimension dim 1, we want to start at position 0 (starting position = 0) and take every second cell (increment = 2) until we have selected two cells (number of elements = 2).
This data selection describes a 3x2 data cube:
Supported Selections
The interface DimensionOnly supports the following kinds of selections:
- Point Selection
- Range Selection
- Advanced Range Selections
In the following sections, these selections and the methods to create them are described.
Point Selection
The method Dimension withDimensionIndex(Long cellIndex) allows selecting a single cell of the dimension.
The following example illustrates how to select one single point of the first dimension by its index position:
JAVA and C#:
DataSelection srcSelection = dataCube.createSelection() //
.withDimensionIndex(0) //
...
.finish();
Range Selection
A data selection may be described by the starting position, the increment and the number of elements to select per dimension.
The methods Dimension withDimensionIndex(Long start, Long stride, Long count) and Dimension withDimensionIndex(String dimension) allow defining range selections and more advanced selections.
The first method takes the following arguments:
start: the index where the selection startsstride: the step size of the selection, e.g. 1 to select each elementcount: the number of elements to select
The second method takes a string as argument that represents the selection on the dimension.
Parameters containing null are filled with the default value. These are 0 for start, 1 for stride and the count of elements until the dimension end considering start and stride.
The following example illustrates the selection of a range of indices from index 0 to index 9 on the first dimension, including every index in between:
JAVA and C#:
DataSelection srcSelection = dataCube.createSelection() //
.withDimensionIndex(0, 1, 10) //
...
.finish();
The following example uses the data selection notation and is equivalent to the previous:
JAVA and C#:
DataSelection srcSelection = dataCube.createSelection() //
.withDimensionIndex("[0:1:10]") //
...
.finish();
The following section illustrates how the stride parameter may be used to define even more powerful selections on indexed dimensions.
Advanced Range Selection
In addition to point and range selections, the ADF-DC API supports additional advanced selections on indexed dimensions.
The methods Dimension withDimensionIndex(Long start, Long stride, Long count) and Dimension withDimensionIndex(String dimension) allow defining advanced selections via the stride parameter. This parameter allows the selection of only every n-th index (n>1) in a defined range.
The following examples illustrate the power and possibilities of the data selection notation [start:stride:count]:
[0:1:1], [0::1], [0:1] or [0] addresses cell 0 (start 0, stride 1, count 1)
[3:2:10] addresses 10 values, starting at index 3 with stride 2
[2::5] or [2:5] addresses 5 values, starting at index 2 with the default stride 1
[3::] or [3:] starts at index 3 and addresses the rest of the dimension (without the ':' it would just address one)
Complete Example
Let's say we have a 100x100 2D Data Cube.The following example illustrates the creation of a data selection to access the complete first column of the Data Cube:
JAVA and C#:
DataSelection tgtSelection = dataCube.createSelection().withDimensionIndex(0).withDimensionAll().finish();
Creating a Data Selection that selects the complete Data Cube
The DataCube interface provides the method DataSelection createSelectionAll() that allows the creation of a Data Selection that selects the complete content of the Data Cube.
Say one has 2D Data Cube and wants to create a Data Selection of the complete Data Cube. The following example illustrates how this might be achieved:
JAVA and C#:
DataSelection dataSelection = dataCube.createSelection() //
.withDimensionIndex("[:]") //
.withDimensionIndex("[:]") //
.finish();
However, this may be achieved more conveniently as shown in the following example:
JAVA and C#:
DataSelection dataSelection = dataCube.createSelectionAll();
Writing into a Data Cube
This section describes writing into a Data Cube. First the principle of writing is illustrated, then the API.
Principle
Writing into a Data Cube is based on the following principle:
A source Data Selection is written to a target Data Selection with the same number of elements.
The values of the source Data Selection are read in the order of the dimensions and written in the same way into the target Data Selection.
The following figure illustrates this concept: On a 3x5 data cube, a 3x2 data selection is created (marked in green). This source data selection is written to a 2x3 data selection (marked in red) on the target 3x3 data cube.

Writing via the API
The DataSelection interface provides several methods to write into a Data Cube.
The following examples illustrate how to write observations into a data cube using the API.
Writing into a Data Cube with One Measure
This section describes how to write into a Data Cube with one measure.
The general pattern is:
- Create a source selection that wraps the observations
- Create the target selection on the Data Cube
- Write the source selection into the target selection
The following Data Cube is used in the next examples to illustrate writing:
JAVA and C#:
DataCube dataCube = dataCubeService.createDataCube(dataCubeIRI, "Data Series") //
.withMeasure(measureXYZ, StandardDataType.INT) //
.withDimension(firstDimension, StandardDataType.LONG, 40) //
.finish();
The following example illustrates writing one observation into this Data Cube at index position 26
using the method void write(DataSelection source):
JAVA and C#:
int[] observation = new int { 67 };
// Create a source selection that wraps the observation
DataSelection sourceSelection = dataCubeService.wrap(observation).createSelectionAll();
// Create the target selection on the Data Cube
DataSelection targetSelection = dataCube.createSelection().withDimensionValue(26).finish();
// Write the source selection into the target selection
targetSelection.write(sourceSelection);
The following example is equivalent to the previous, but uses the convenience method void write(int[] values) instead of a source selection:
JAVA and C#:
int[] observation = new int { 67 };
// Directly write the observation into the target selection
dataCube.createSelection().withDimensionValue(26).finish().write(observation);
Writing into a Data Cube with Multiple Measures
This section describes how to write into a Data Cube with multiple measures.
The general pattern is very similar to the one when writing one measure. When having multiple measures, one has to select the measure to write into. This means that the method DataSelection write(Property measure, DataSelection source) must be used instead of void write(DataSelection source).
The following Data Cube is used in the next examples to illustrate writing:
JAVA and C#:
// Creates a DataCube with one dimension and two measures.
IRI dataCubeIri = ...
DataCube dataCube = dataCubeService //
.createDataCube(dataCubeIri, "DataCube With Multiple Measures") //
.withMeasure(measureX, StandardDataType.INT) //
.withMeasure(measureY, StandardDataType.DOUBLE) //
.withDimension(firstDimension, StandardDataType.LONG, 10) //
.finish();
The following example illustrates writing observations having multiple measures into this Data Cube:
JAVA and C#:
// The values for the measures
int[] firstValues = new int[] { 1, 4, 9, 16, 25, 36, 49, 64, 81, 100 };
double[] secondValues = new double[] { 1.002, 1.987, 2.99, 4.0, 5.03, 5.89, 6.95, 8.009, 9.05, 10.03 };
// Wrapping them as DataCubes and creating (source) selections.
DataSelection firstSelection = dataCubeService.wrap(firstValues).createSelectionAll();
DataSelection secondSelection = dataCubeService.wrap(secondValues).createSelectionAll();
// Writing them into the DataCube to the respective measure
dataCube.createSelectionAll().write(measureX, firstSelection).write(measureY, secondSelection);
To summarize: One write operation per measure is required in order to write observations having multiple measures.
Reading from a Data Cube
This section describes reading from a Data Cube.
The principle for reading is the same as for writing, only vice versa: Because of this, the API does not offer a new, separate method for reading, instead the one for writing can be reused.
The general pattern for reading is:Principle
a source data selection is written into a target data selection. General pattern
Reading via the API
The following sections describe reading from Data Cubes via the ADF-DC API.
Reading from a Data Cube with One Measure
The following example illustrates reading out the observation written in a previous example:
JAVA and C#:
// Create a Data Selection on the source Data Cube
DataSelection srcSelection = dataCube.createSelection().withDimensionIndex(26).finish();
// Query the number of values that it contains
int size = srcSelection.getValueCount();
// Create a data structure of the correct size to hold these values
int[] writtenObservation = new int[size];
// Wrap this data structure into a Data Cube and create a complete Data Selection on it
DataSelection tgtSelection = dataCubeService.wrap(writtenObservation).createSelectionAll();
// Read the source Data Selection into the target Data Selection
tgtSelection.write(srcSelection);
// Do something with resultData
// e.g. in Java System.Out.println(writtenObservation[0]); --> 67
// or in C# Console.WriteLine(writtenObservation[0]); --> 67
Reading from a Data Cube with Multiple Measures
This section describes reading from a Data Cube with multiple measures.
Analog to writing a Data Cube with Multiple Measures, one has to select the measure to read from, using the method DataSelection write(Property measure, DataSelection source).